V7: The timeline is taking shape
Making progress with sketches, wireframes, and a prototype
Though it’s mostly taken place in scattered, stolen moments, I’ve made a lot of progress on the UX of the timeline section, much of which was still a disconcerting mystery not so long ago.
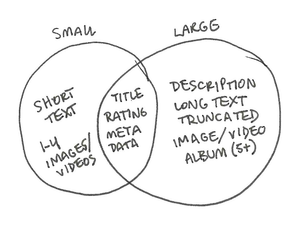
With the help of the data categories and content inventory I established in the previous post, I’ve settled on a binary timeline concept: each post is either small or large. Small posts consist of up to 100 words and/or up to four images/videos. They’ll be represented on the timeline in their entirety. Large posts consist of 100 or more words and/or more than four images/videos. They’ll be represented on the timeline in truncated form. (I know truncation is not a content strategy, but I’m giving it a shot anyway.) As timeline nodes, small and large posts alike will be constructed according to their needs from a shared library of elements.
- Date/time: One of only two elements every timeline node includes (the other is Source).
- Series indicator: Denotes that the post is directly related to at least one other post. It links to a timeline of that series. For now, the quick and dirty form it takes in the wireframes is “• • •”.
- Source: Where the post was originally published, probably represented by a favicon.
- Title
- Description
- Location: Only for posts for which location is relevant (e.g. events). Available data is a mixed bag, but candidates include Flickr, Instagram, Letterboxd, Tinnitus Tracker, Twitter.
- Short text: Up to 100 words.
- Long text: 100 or more words, truncated, with a link to the full post.
- Image/video carousel: Up to four images/videos.
- Image/video cluster: More than four images/videos, with a link to the full post.
Wireframes
I made some wireframes of small and large timeline nodes with the maximum amount of content each could have. (I made the wireframes in Sketch, which, in addition to Figma, I’m finally coming around to after years of avoiding them.)


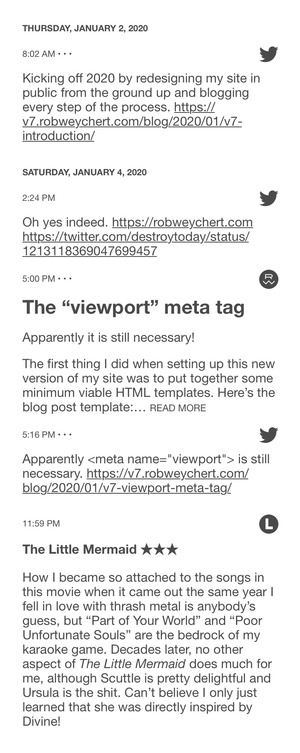
And here is an excerpt from a wireframe with actual content from January 2020 that helped me get a sense of how the timeline nodes would work in aggregate:
{kind=link}
Filters
When I started, I didn’t think my January was a very active month, but its timeline has 45 nodes, which is certainly not nothing. This was a good excuse to start thinking about how filters could work, a concept which quickly evolved from sketch…
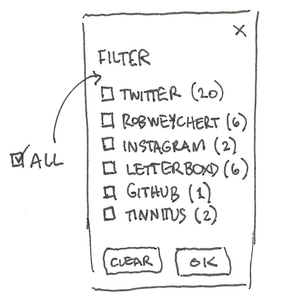
…to wireframe…
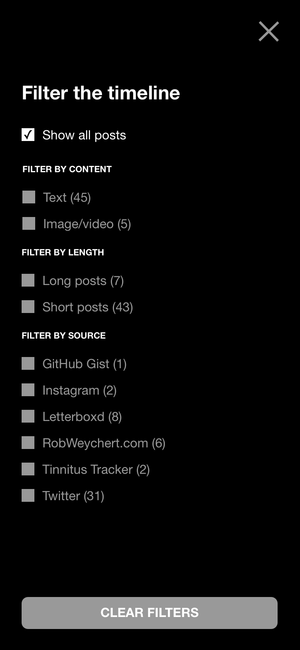
…to getting way ahead of myself and spending an entire weekend building a functional prototype. If you have JavaScript enabled, you can try it:
I’ll go into more detail on the prototype and what I learned from it in a future post.
Other developments and next steps
A few other things this process helped clear up, at least for now:
- I’m not going to get precious about taxonomy. As far as I’m concerned, this aggregated content is a log of my activity on the web, which makes it my weblog. So /blog/ is where it will all live.
- There will be three RSS feeds: one for small posts, one for large posts, and one for everything.
- Duplicate content, such as an image that was posted to both Flickr and Twitter, or a Tinnitus Tracker post whose primary content is an Instagram video, will only appear in the timeline once, from its initial source.
- Twitter replies (other than replies to myself for the sake of threading) will be omitted. I don’t think their inclusion would be without value, but in general, my site’s content should probably have an intended audience larger than one person.
The next step will be some light user testing to see if my wireframes’ and prototype’s assumptions are validated. If you’d like to be a part of that process by trying out the filter prototype above and letting me know if it does or doesn’t work the way you expected, please do!